Data Compression
|
In data transfer, there is a limit on how much data can be transferred at once. Even if it is possible, overloading data can cause slow transfer or disruptions. The same applies for data storage. This is why data compression is used. Data compression does what it suggests: compresses or minimises data so that more data can be transferred or stored for the same limits. Without data compression, data transfer will be slow and very restrictive.
|
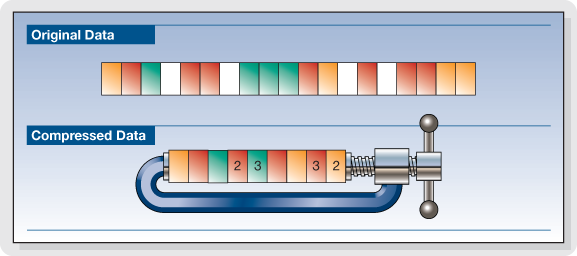
Basic compression techniques are easily explained through a sample piece of data:
32000114122220000011410004444432…
Null compression is when strings of nulls (0s) are replaced by a compression code, along with how many null signals are repeated. If {=(3 of nulls)} was the compression code the sample data may be compressed like so:
32{=3}11412222{=5}1141{=3}4444432…
Run-length compression is a developed version for null compression. Instead of merely spaces being replaced, all repetitions more than 3 characters long were replaced by a compression code, one of the characters and the number of repeated characters. This can compress almost 98% of data. If +[(replaced character),(# of repeated characters)] was the compression code, the above text may be replaced like so:
32{=3}1141+[2,4]{=5}1141{=3}+[4,5]32…
Keyword encoding recognises any common repeated sequence of characters and replaces them with a designated code. If 1141 was replaced by a and 32 was replaced by e, the above data will become:
e{=3}a+[2,4]{=5}a{=3}+[4,5]e…
Notice how different the data coding looks. It is definitely more concise and confusing to look at. However, this is what computing software is used to. Assume the compression programming is the same for the receiving device, the compressed data will be able to be deciphered by reversing the processes.
32000114122220000011410004444432…
Null compression is when strings of nulls (0s) are replaced by a compression code, along with how many null signals are repeated. If {=(3 of nulls)} was the compression code the sample data may be compressed like so:
32{=3}11412222{=5}1141{=3}4444432…
Run-length compression is a developed version for null compression. Instead of merely spaces being replaced, all repetitions more than 3 characters long were replaced by a compression code, one of the characters and the number of repeated characters. This can compress almost 98% of data. If +[(replaced character),(# of repeated characters)] was the compression code, the above text may be replaced like so:
32{=3}1141+[2,4]{=5}1141{=3}+[4,5]32…
Keyword encoding recognises any common repeated sequence of characters and replaces them with a designated code. If 1141 was replaced by a and 32 was replaced by e, the above data will become:
e{=3}a+[2,4]{=5}a{=3}+[4,5]e…
Notice how different the data coding looks. It is definitely more concise and confusing to look at. However, this is what computing software is used to. Assume the compression programming is the same for the receiving device, the compressed data will be able to be deciphered by reversing the processes.
